JPA를 사용할 때, 엔티티의 데이터를 변경한 후 save() 메서드를 호출해야만 쿼리가 실행된다고 생각하는 경우가 많다. 그러나 이는 JPA의 핵심 기능 중 하나인 더티 체킹(dirty checking) 개념을 이해하지 못한 데서 비롯된 오해다.
영속성 컨텍스트에 관리되는 엔티티에 한해서는 save()는 의미가 없다.
이 글에서는 Spring Data JPA의 save()가 언제 쿼리를 날리는지, 그리고 더티 체킹과 어떤 차이가 있는지 예제와 함께 정리한다.
더티 체킹(DIRTY CHECKING)이란?
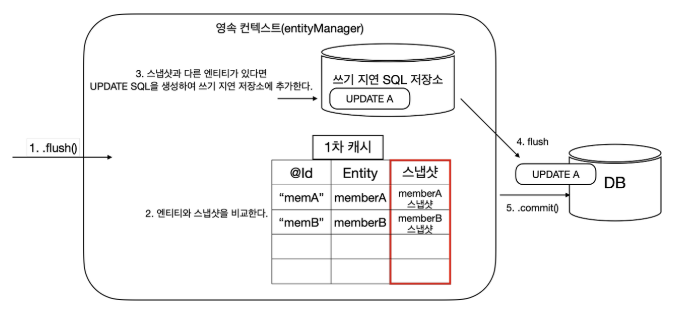
더티 체킹이란 JPA가 트랜잭션 내에서 영속 상태로 관리되는 엔티티의 변경 여부를 감지하고, 트랜잭션이 종료되는 시점에 자동으로 update 쿼리를 수행하는 기능이다. 이 기능 덕분에 개발자는 명시적으로 save()를 호출하지 않아도 변경된 내용을 데이터베이스에 반영할 수 있다.
더티 체킹이 실행되기 위해선 아래와 같은 조건이 있다.
- 엔티티가 영속 상태(Persistent) 여야 한다
- 트랜잭션 안에서 엔티티의 필드를 변경했을 때
- flush 시점 (보통은 트랜잭션 commit 직전에 자동 flush됨)
예를 들어, 다음과 같은 코드가 있다고 가정해보자.
@Transactional
public void updateTodo(Long id, String newTitle) {
Todo todo = todoRepository.findById(id).orElseThrow();
todo.setTitle(newTitle); // setter만 호출
}
위 코드에서는 save() 메서드를 호출하지 않았지만, 트랜잭션이 종료될 때 Hibernate는 todo 객체의 변경사항을 감지하여 update 쿼리를 자동으로 생성한다(더티체킹) .
그렇다면 save()는 언제 필요한가?
결론만 말하자면 save()는 영속성 컨텍스트에서 관리되지 않는 엔티티를 DB에 저장해야하는 경우에만 필요하다.
Spring Data JPA의 save() 메서드 내부는 isNew()라는 판별 메소드가 있는데, 해당 메소드안에서 조건에 따라 다르게 작동한다.
isNew()는 다음 조건에 따라 동작한다.
public boolean isNew(T entity) {
ID id = this.getId(entity);
Class<ID> idType = this.getIdType();
if (!idType.isPrimitive()) {
return id == null;
} else if (id instanceof Number) {
Number n = (Number)id;
return n.longValue() == 0L;
} else {
throw new IllegalArgumentException(String.format("Unsupported primitive id type %s", idType));
}
}
- 신규 엔티티(id == null || id == 0L)인 경우 => EntityManager.persist()를 호출하여 insert 쿼리를 실행한다.
- 기존 엔티티(id != null || id != 0L) 이 아닌 경우 => EntityManager.merge()를 호출하여 병합 과정을 수행한다.
사실상, 객체를 영속화 시키는 과정이라고 볼 수 있다.
여기서 persist()와 merge()를 다시 짚어보자.
1. persist
- 새로운(비영속) 엔티티를 영속 상태로 만듦
- 즉, 아직 ID가 없는 "처음 만든 객체"를 영속성 컨텍스트에 등록한다
- 이후 트랜잭션이 flush될 때 insert 쿼리가 실행된다
- persist()는 이미 영속성 컨텍스트에 있는 엔티티에 대해 호출하면 예외가 발생한다.
2. merge
- 비영속 또는 준영속(detached) 상태의 엔티티를 병합하여 영속 상태로 만듦
- 영속성 컨텍스트(1차 캐시)에 동일한 ID가 존재하면 그 객체를 사용하고, 없으면 DB에서 select로 로딩한다
- DB에도 없으면?
- JPA는 새로운 영속 엔티티를 만들어 복사본을 생성하고, 이를 영속화한다.
- 그리고 트랜잭션 flush 시 insert 쿼리를 실행한다.
- 이후 변경 사항은 더티 체킹 대상이 된다.
영속화를 persist로 하든 merge로 하든 영속화 된 객체에 대해선 더티체킹은 항상 실행될 수 있다.
persist는 insert 쿼리를 실행하기 때문에 더티체킹이 필요 없을 뿐이다.
save() 사용시 주의사항
그럼 id가 GeneratedValue(strategy = GenerationType.IDENTITY) 인 경우가 아니라, 수동으로 만들어 save() 한다면 어떻게 될까? 기존 엔티티로 취급하여 merge하기 때문에 select 될 것이다. 따라서 insert만 해도 되는데 불필요한 select 쿼리까지 실행되는 것이다. 이를 해결하기 위해서 객체에서 Persistable 인터페이스를 구현하고 isNew()를 오버라이드하는 방법이 있다.
아래는 예시다.
package com.mallapi.mall.domain;
import jakarta.persistence.*;
import lombok.*;
import org.springframework.data.domain.Persistable;
@Entity
@ToString
@Getter
@Setter
@Builder
@NoArgsConstructor
@AllArgsConstructor
@Table(name = "tbl_todo")
public class Todo implements Persistable<Long> {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
// isNew()가 항상 true를 반환해 persist()로 동작
@Override
public boolean isNew() {
return true;
}
}
실습 예제: save()와 더티 체킹 비교
다음은 테스트 코드에서 findById()를 통해 조회한 엔티티에 값을 변경하고 save()를 호출한 예제다.
@Test
@Transactional
@Rollback(false)
public void testSaveCall() {
Todo todo = todoRepository.findById(1L).orElseThrow();
todo.setTitle("변경 - save 호출");
todoRepository.save(todo); // 이미 영속 상태
log.info("After Save: {}", todo);
}
Hibernate:
select
t1_0.id,
t1_0.complete,
t1_0.content,
t1_0.due_date,
t1_0.title
from
tbl_todo t1_0
where
t1_0.id=?
Hibernate:
update
tbl_todo
set
complete=?,
content=?,
due_date=?,
title=?
where
id=?
여기서 주목할 점은 save() 호출 시 별도의 select 쿼리가 발생하지 않는다는 점이다. 이는 todo 객체가 이미 영속 상태이기 때문에, save()는 내부적으로 merge()를 호출하더라도 select 없이 1차캐시(영속성 컨텍스트)에서 조회되며, 이후 더티 체킹에 의한 update만 수행된다.
여기서 주의할 점은 JPA의 영속성 컨텍스트(Persistence Context)는 트랜잭션 안에서만 유지된다. 따라서, 만약 @Transactional이 없다면 findById로 가져온 객체는 detached(준영속) 상태일 것이고, save(todo) 호출 시 select + update 쿼리가 실행된다. 영속성 컨텍스트가 없으므로 더티체킹도 되지 않는다. 따라서 트랜잭션 어노테이션을 빼먹지 말도록 하자.
반대로 save()가 필요한 경우
save()가 실제로 의미를 가지는 경우는 다음과 같다.
1. 비영속(new) 객체를 저장할 때
Todo newTodo = new Todo();
newTodo.setTitle("새로운 할 일");
todoRepository.save(newTodo); // persist → insert 쿼리 발생
2. 준영속(detached) 객체를 다시 병합할 때
Todo detached = new Todo();
detached.setId(1L);
detached.setTitle("준영속 상태");
todoRepository.save(detached); // merge → select + (insert 또는 update) 발생
이 경우에는 JPA가 해당 ID를 가진 엔티티가 존재하는지 DB에서 조회한 뒤 병합을 수행하므로 select 쿼리가 발생한다.
정리: save() vs 더티 체킹
| 상황 |
쿼리 발생 |
save() 의미 |
| 영속 상태 객체 수정 후 save() 호출 |
update 1회 |
merge 호출이지만, 이미 컨텍스트에 있으므로 아무 일도 안 함 (더티 체킹만) |
| ID 있는 비/준영속 상태 객체 save() 호출 |
select + update (DB에 있으면) /
select + insert (DB에 없으면) |
Merge 실행 |
ID 없는 비/준영속 상태 객체 save() 호출
(이 경우 ID가 auto increment여야함) |
insert |
Persist 실행 |
결론
- findById()로 조회한 객체는 이미 영속 상태이므로, 값을 변경하기만 해도 트랜잭션 종료 시점에 더티체킹에 의해 자동으로 update된다.
- 이 경우 save()를 호출하는 것은 불필요하며, 코드 가독성에도 혼동을 줄 수 있다.
- save()는 영속성 컨텍스트에서 관리되지 않는 신규 객체 또는 비/준영속 객체일 경우에만 필요하다.
JPA를 효과적으로 활용하기 위해서는 **엔티티의 생명주기(영속/준영속/비영속)**를 잘 이해하는게 중요하다.